top 명령어 제대로 알고 쓰자 본문
top 명령어로 확인하는 프로세스 정보
리눅스 환경에서 사용하는 top 명령어는 주로 동작하고 있는 프로세스의 정보를 손쉽게 확인하여 리눅스 시스템의 상태를 전반적으로 빠르게 확인할 수 있는 명령어다.
top 명령어를 사용하게 되면 프로세스의 상태가 여러 수치들과 함께 화면에 표현되는데 이 수치들이 각각 어떤 의미를 가지고 있는지 알아보도록 하자.
각 수치가 의미하는 정보

- 현재 서버의 시간과 서버의 구동 시간이 표시된다.
- 사용자가 몇 명이나 로그인해 있는지, 시스템의
Load Average는 어느 정도인지 보여준다.Load Average란 현재 시스템이 얼마나 많이 동작하고 있는지 보여주고 있는 지표로 해당 수치가 높으면 높을 수록 서버가 열심히 일하고 있다는 것을 의미한다.
- 현재 시스템에서 구동 중인 프로세스의 수를 나타낸다.
CPU,Memory,Swap메모리의 사용량을 의미한다.PR은 프로세스의 실행 우선 순위, 즉 다른 프로세스들보다 먼저 실행되어야 하는지의 여부를 의미힌다.NI는PR을 얼마나 조정할 것인지를 결정한다. 기본PR값에NI를 더해 실제PR의 값이 결정된다.VIRT,RES,SHR에 대해서는 아래에서 더 자세히 설명S는 프로세스의 상태를 나타낸다.VIRT, RES, SHR이 세 가지 항목은 프로세스가 현재 사용 중인 메모리에 대한 값이다.
VIRT는 프로세스가 사용 중인 가상 메모리의 전체 용량이다. 즉, 프로세스에 할당된 가상 메모리 전체의 크기를 나타낸다.
RES는 현재 프로세스가 사용하고 있는 물리 메모리의 양을 의미한다. 이는 프로세스에 할당된 가상 메모리 VIRT 중 실제로 메모리에 올려서 사용하고 있는 메모리의 크기를 나타낸다.
마지막으로, SHR은 프로세스가 다른 프로세스와 공유하고 있는 공유 메모리의 양을 의미한다. 주로 라이브러리가 이에 해당될 수 있다.

VIRT의 경우에는 실제로는 할당되지 않은 가상의 공간이기 때문에 해당 값이 크다고 해도 문제가 되진 않는다. 실제로 프로세스가 사용하고 있는 메모리는 RES 영역이기 때문에 메모리 점유율이 높은 프로세스를 찾기 위해서는 RES 영역이 높은 프로세스를 찾아야 한다.
Memory Commit - VIRT와 RES는 왜 구분될까?
VIRT로 표현되는 가상 메모리는 프로세스가 커널로부터 사용을 예약받은 메모리라고 생각할 수 있다.
예를 들어, 프로세스는 malloc()과 같은 시스템 콜을 사용해 자신이 필요로 하는 메모리의 영역을 할당해 줄 것을 요청한다. 이에 대해 커널은 가용 가능한 공간이 있다면 성공 메시지와 함께 해당 프로세스가 사용할 수 있도록 가상의 메모리 주소를 전달한다.
하지만 성공 메시지가 전달 됐다고는 해도 물리 메모리에 해당 영역이 할당된 상태는 아니라는 것이다.

이런 동작 방식을 Memory Commit이라고 한다.
이후 프로세스가 할당받은 메모리 영역에 실제로 쓰기 작업을 진행하면 Page fault가 발생하며, 해당 시점에 커널은 실제 물리 메모리에 프로세스의 가상 메모리 공간을 매핑한다. 이는 Page Table 이라고 하는 커널의 전역 변수로 관리된다.
이렇게 실제 물리 메모리에 바인딩된 영역이 RES로 계산된다.
그렇다면 Memory Commit과 같은 방식을 사용해 실제 물리 메모리를 프로세스에 할당하는 시기를 지연시키는 이유는 무엇일까?
주요한 이유는 새로운 프로세스를 만들기 위한 콜을 처리해야 하기 때문이다. fork() 시스템 콜을 사용하면 커널은 현재 실행 중인 프로세스와 똑같은 프로세스를 하나 더 만들게 되는데, 대부분 fork() 후 exec() 시스템 콜을 통해 전혀 다른 프로세스로 변화하게 된다.
fork() 후 exec()로 프로세스를 변화시키는 이유
프로세스가 생성될 때 프로세스는 고유의 주소 공간을 가지게 된다. fork() 시스템 콜을 사용해 부모 프로세스를 복사하게 되면 주소 공간까지 동일하게 복사하게 되는데, 이때 Code, Data, Stack, Program Counter까지 모두 복사되기 때문에 복사된 자식 프로세스는 부모 프로세스가 실행한 부분부터 실행하게 된다.
이렇게 되면 시스템의 프로세스는 모두 똑같이 동작하기 때문에 exec()를 통해 새롭게 프로세스를 덮어씌워야 한다.
따라서 이 과정에서 확보한 메모리 영역이 쓸모없어지기 때문에 COW (Copy-On-Write) 기법을 통해 복사된 메모리 영역에 실제 쓰기 작업이 발생한 후에 실제적인 메모리 할당을 시작하는 것이다.
COW 기법을 사용하기 위해서는 실제 물리 메모리에 할당하는 시기를 지연시키는 Memory Commit이 필수적이다.
현재 시스템의 Memory Commit의 상태는 sar 명령어를 통해 확인할 수 있다.

위의 사진에서 %commit의 숫자는 시스템의 Memory Commit의 비율을 나타낸다. 즉, 할당만 되고 실제로 사용되지 않는 메모리의 양이 전체 메모리의 5.05 정도라는 것이다.
수치가 낮다면 순간적으로 해당 메모리에 쓰기 작업이 들어가더라도 전체적으로는 문제가 없지만, 만약 수치가 높다면 순간적으로 시스템에 부하를 일으키거나 커널 응답 불가 현상을 발생시킬 수 있다.
따라서, 커널은 Memory Commit에 대한 동작 방식을 vm.overcommit_memory라는 파라미터로 제어할 수 있도록 했다.
vm.overcommit_memory는 0, 1, 2 세 가지 값으로 설정할 수 있다.
- 0 : 기본 설정 값으로, overcommit 할 수 있는 최댓값은 page cache와 swap 영역 그리고 slab reclaimable 이 세 값을 합한 값이 된다. 현재 메모리에 가용 공간이 얼마나 존재하는지는 고려하지 않는다.
- 1 : 아무 것도 계산하지 않고 요청 온 모든 메모리에 대해
commit이 발생한다. - 2 : 제한적으로
commit을 진행한다. 계산식이 존재하며vm.overcommit_ratio에 설정된 비율과swap영역의 크기를 토대로 계산된다.
slap reclaimable?
slab reclaimable은 Slab 메모리 중에서 필요한 경우 다시 회수(reclaim) 할 수 있는 메모리의 양을 의미한다. Slab 메모리는 커널이 사용하는 구조체나 객체를 저장하기 위해 할당되며, 커널 공간에서 관리된다.사용하지 않을 때는 주로 캐시를 위해 할당되는 경우가 많으며, 시스템 메모리가 부족할 때 해제하여 다른 용도로 사용할 수 있다.
vm.overcommit_memory을 통해 swap 영역이 프로세스에 할당되는 commit memory를 결정하는데 큰 역할을 한다는 것을 알 수 있다.
프로세스의 상태 확인
프로세스의 상태는 SHR 옆에 있는 S 항목을 통해 확인할 수 있다.
D-uninterruptible sleep상태로, 디스크 혹은 네트워크 I/O를 대기하고 있는 프로세스를 의미한다. 이 상태의 프로세스들은 대기하는 동안Run Queue에서 벗어나Wait Queue로 들어가게 된다.R-running상태로, 실제로 CPU 자원을 소모하며 실행 중인 프로세스를 의미한다.S-sleeping상태의 프로세스로,D상태의 프로세스와의 차이점은 요청한 리소스를 즉시 사용할 수 있는지의 여부다.T-traced or stopped상태로,strace명령어 등으로 프로세스의 시스템 콜을 추적하고 있는 상태를 보여준다.Z-zombie상태의 프로세스로 부모 프로세스가 죽은 자식 프로세스를 의미한다.

좀비 상태 프로세스의 경우 스케줄러에 의해 선택되지 않기 때문에 CPU를 사용하지 않고, 이미 사용이 중지된 프로세스이기 때문에 메모리 또한 사용하지 않는다.
하지만, PID를 점유하기 때문에 좀비 프로세스가 쌓이다 보면 PID가 고갈되게 되고 PID 할당이 불가능해진다.
프로세스의 우선 순위
PR과 NI는 커널이 프로세스를 스케줄링할 때 사용하는 우선순위를 나타내는 값이다.
참고로 프로세스 스케줄링이 진행되는 구조는 다음과 같다.

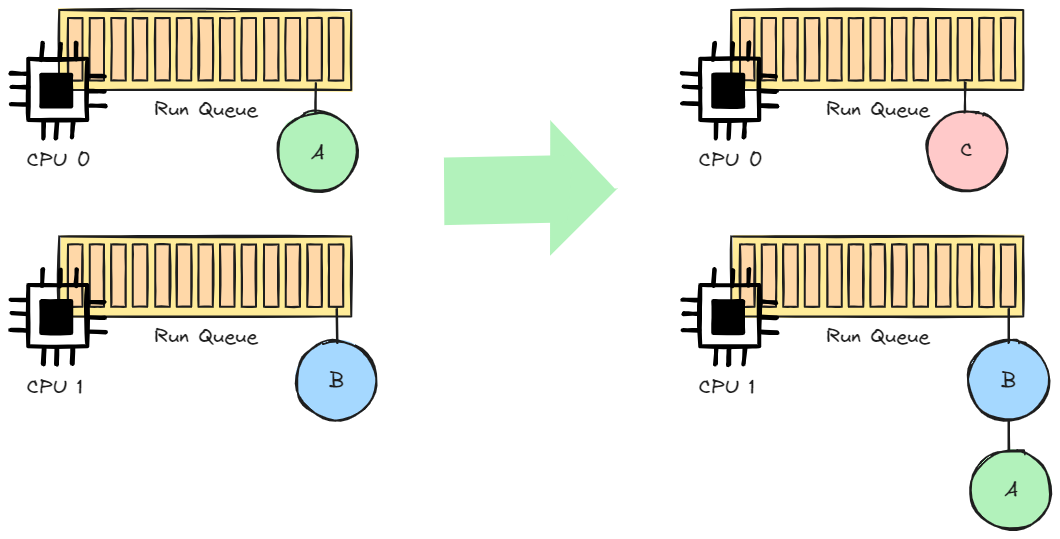
CPU마다 Run Queue라는 것이 존재하며, Run Queue에는 우선순위 별로 프로세스가 연결되어 있다.
스케줄러는 유휴 상태에 있던 프로세스가 깨어나거나 특정 프로세스가 스케줄링을 양보하는 등의 경우에 현재 Run Queue에 있는 프로세스들 중 가장 우선순위가 높은 프로세스를 꺼내서 디스패처에 넘겨준다.
디스패처는 현재 실행 중인 프로세스의 정보를 다른 곳에 저장한 후 넘겨받은 프로세스의 정보를 가지고 다시 연산하도록 요청한다.
이러한 프로세스 스케줄링 과정에서 프로세스의 실제 우선순위 값을 의미하는 것이 바로 PR이며, nice 명령어를 통해 우선순위 값을 낮추는데 이를 표시하는 값을 NI라고 한다.
기본적으로 모든 프로세스는 20의 우선순위를 갖는데, 여기에 nice 명령어를 통해 NI 값을 변경하게 되면 우선순위가 바뀐다.
이때 유의해야 할 점은 프로세스의 우선순위를 낮췄다고 해도, CPU 코어의 수와 동일한 프로세스가 실행되고 있다면 경합이 발생하지 않기 때문에 비슷한 시간에 종료되게 된다.
만약 동일한 우선순위를 가진 A, B 프로세스가 실행 중일 때 새롭게 우선순위가 낮은 C 프로세스가 생성되면, A 프로세스는 다른 CPU의 Run Queue로 옮겨간다.
Load Average
Load Average란 R, D 상태에 놓여있는 프로세스 개수의 1분, 5분, 15분마다의 평균 값을 나타내는 값이다. 이는 얼마나 많은 프로세스가 실행 중이거나, 실행 대기 중인지를 의미하는 수치이다.
Load Average가 높다는 것은 많은 수의 프로세스가 실행 중이거나 I/O 처리를 위해 대기 상태에 있다는 것이며, 낮다는 것은 실행 중이거나 대기 중인 프로세스가 적다는 것을 의미한다.
프로세스의 수를 헤아리는 값이기 때문에 CPU의 코어 수에 따라 값의 의미는 상대적이다.
Load Average가 높은 상황일 때 우리는 그 원인을 파악해야 하는데, 이를 위해서는 CPU를 점유하고 있는 프로세스가 많다는 의미인지 I/O 병목 때문에 I/O 대기 중인 프로세스가 많은 것인지 알아낼 필요가 있다.
부하를 일으키는 프로세스는 CPU 자원을 많이 차지하는 nr_running이라 불리는 프로세스와 nr_uninterruptible로 표현되는 I/O 바운드 프로세스 크게 두 종류로 나눌 수 있다.
top 명령어로는 구체적으로 어떤 부하가 발생하고 있는지 파악하기 어렵기 때문에 vmstat 명령어를 통해 부하의 원인을 명확하게 살펴볼 수 있다.

첫 번째 열의 r은 CPU 자원을 소모하는 nr_running 프로세스의 개수를 나타내고 b는 I/O 자원을 차지하고 있는 nr_uninterruptible 프로세스의 개수를 나타낸다.
'DevOps' 카테고리의 다른 글
| [o11y] Intro-to-mltp (0) | 2025.03.11 |
|---|---|
| Observability (O11y) (0) | 2025.03.10 |
| jdeps와 jlink를 활용한 Java 기반 컨테이너 경량화 (1) | 2024.09.12 |
| [Terraform] 테라폼 기초 (3) (1) | 2024.08.28 |
| [Terraform] 테라폼 기초 (2) (0) | 2024.08.19 |


